テキストファイルとは
2016年9月21日
テキストという言葉と「テキストファイル」
![]() 「テキストファイル」の中の「テキスト」という言葉は、
日常会話では教科書とか参考書のような意味合いになりますね。
「テキストファイル」の中の「テキスト」という言葉は、
日常会話では教科書とか参考書のような意味合いになりますね。
ですが、コンピューター関連、ウェブ制作の現場などでファイルの種類としてあえて
「テキスト」と呼ぶファイル形式は教科書という意味ではありません。
ざっくり言うと「何の装飾もない文字情報の塊」でしょうか。
他に何の装飾・加工もないテキスト情報であることを強調する場合、「プレーンテキスト」と
呼ぶ場合もあります。
たくさんの種類のコンピュータがありますが「テキストファイル形式」で保存は可能で、
その形式で保存したものを「テキストファイル」と呼びます。
対象のアプリケーションを指定しない汎用のテキストファイルは、「.txt」という拡張子を付けますが、UNIXなどで利用する場合は付けない場合も多いです。
拡張子を付けるのは、ファイルの中身がテキストということを明示しているわけで、とくにWindowsやMac OSなどで利用する場合は、付ける必要があります。
でないと、ファイルをクリックした時に適切なアプリケーションが起動しません。
このテキストファイルを読み込み、編集するソフトウェアを
「テキストエディタ」と呼びます。
テキストファイルは最も基本的なファイルフォーマットでもあります。
この業界に関わる者なら特に深く考える人もいないでしょう。
当たり前のことのように普通に接して(使って)いると思います。
ところがコンピュータに詳しく無い人、初めて「テキストファイル」なる言葉を
知ったような人に説明するのはすごく難しい、そして本当に困ってしまいます。
なぜかというと、しっかり理解できるような説明をしようとすると、コンピューターの
基礎概念から順序だてて説明する必要があるからです。
WordやExcelなどで保存したデータは、それぞれのアプリでのみ編集出来ます。
というのはデータファイルが専用のファイル形式だからです。
このようなデータファイルは、文字そのものの情報の他に、文字の大きさ、色、配置情報など付加情報も
同時に埋め込まれていますので、テキストエディタでは編集出来ません。
他方、テキストファイルは、文字・文章を対象とするソフトウェアなら、おそらく
ほとんどのもので、読み込んだり編集することができます。
これは「テキストファイル」が、何も付加情報のないシンプルな文字データのみの情報であるためです。
色々なアプリケーションのデータファイルとして利用されている
HTMLファイルもテキストファイルです。
拡張子が「.html」となっているだけで、ファイルフォーマット(データの中身、形式)としてはテキストファイルそのものです。
テキストファイルをアプリケーションのデータファイルとしているケースはたくさんあります。
例として拡張子で示すと .css .js .json .xml .csv .pl .php .rbなどです。
まあ、基本的プログラム言語のほとんど(全てかもしれません!)のソースファイルはテキストファイルですし、
perl php phython ruby などUNIX OSなどで動作する高級スクリプト言語のプログラムはすべてテキストファイルです。
それぞれ、.pl .php .py .rb という拡張子を付けてどの言語のソースか区別できるようにしています。
コンピュータ、インターネットを形成する主役としてUNIX OSががありますが、
UNIXでのデータファイルの定番はテキストファイルです。
何より、プログラム、データファイルの編集には、テキストエディタ一つですべてOKというシンプルな
方法を選択したことで、UNIX OS全体の風通しがよくなり、ここまで発展したように思います。(OPENソースと
いうことも大きな要因ではあると思いますが・・)
一方、Lotus123 とか、Word Excel など、主にWindows MacOSなどの商用のソフトウェアは、
ソフトウェアを販売することが一番大きな目的ですので、ユーザの囲い込み、他社のソフトでの利用防止
など販売戦略的な考えがあって、専用データファイル形式となりました。
テキストファイルの真実を説明の前に
さて、「テキストファイル」の説明をする前に、まったく関係ないような2進数の話とか、
改行コードとか、ISOなんとかとか、ちょっと難しい話が続きますが、
いろいろ考えた末に私の結論として、そういうことを理解していないとテキストファイルの理解が
完全には出来ないと思いましたので、割愛せず記述します。
例えば、ウェブデザイナーの人であれば、ネットの解説を読んでいる時、改行コードは
0A 0Dであるとか、10進数なら13だとか、
また何かの文字コードは、 EFだとか、FFだとか一度は目にされたこともあるかと思います。
ぼんやりとでも理解するためにも、ざっと目をとおして下さい。
コンピュータの仕組みをすこし理解しましょう
現在のコンピュータはLSI(※注)を利用し情報の記憶、計算処理を行います。
計算処理を行う前に、処理の対象となる情報は何らかの形で記憶回路に保存されてることが前提ですが、
その情報もどのような形で保存されているのか、どのような単位(かたまり)で受け渡しをするのか?
イメージを掴んでおくと理解が早いと思うので説明してみます。
※ LSI・半導体
コンピュータの頭脳になったり、記憶する回路は半導体の特性を生かして一つの基板上にまとめて
つくられるようになりました。 これをIC(集積回路)と呼びますが、年々その集積度が上がり、
特に高密度に集積したものをLSI(大規模集積回路)と呼びます。 現在では当時のLSIからするとすでに、
何万倍もの高集積化となっているようです。
コンピュータは電気回路が主たる仕組みですので、情報の記憶も電気の作用を利用します。
例えば、ある一つの記憶領域に、0 か 1 の情報を保持し、参照・変更することが出来ますが、
仕組みとして、電気の特性である電圧を利用しています。
(※ 記憶素子については、専門的な電気回路の説明を長く記述しなければならない為、割愛)
ある記憶領域の電圧が高ければ1 低ければ 0 というわけです。
この一つの記憶領域を bit(ビット)と呼びます。
任意のデータをこの素子に保持し利用するには、このbitと呼ぶ記憶素子を
いくつかまとめて、操作出来るようにする必要があります。
記憶素子の利用はその後、bitは8つまとめて操作するのか一番使い勝手が良いということで標準となりました。
bit が8つまとまったものをbyte(バイト)と呼びます。
なんらかの文字を表す最小単位のこのbyteは現在でもコンピュータの技術の基礎であり、
文字情報の単位としてなくてはならない概念であり、決め事となっています。
※ Byte(バイト)
本来byteはキャラクタや、特定の文字などbitを使って個別に1文字を認識する意味合いで
あったらしいですが、1980年代頃から一般的に8bit → 1byte が定着したようです。
- ◆ 2進数
-
1 バイト/Byte(8bit)の情報を表現するには、1 か 0 の組み合わせなので、01010101 とか
10101010 のような表記になります。
この1、0の並びを値として考えた場合、そのまま2進数を表しているわけで、このことからコンピュータと 2進数はすごく深い関わりがあるわけです。
2進数では2は使いません。2になると次の桁へ位が上がるからです。
10進数で表わせる数 0 1 2 3 4 5 6 7 は 2進数で表わすと → 0000 0001 0010 0011 0100 0101 0110 0111 となります。
0と1で数を表しますので、コンピュータの記録特性を考えた場合ぴったりの良い方法となったわけです。
ただ0と1の並び、例えば、 10111001 とかの情報は人間が判別するには 非常にやっかいです。
そこでいつからか16進数という概念を利用しましょうということになりました。
「2進数の0と1の並びはほんとに見分けにくいけど、 16進数で表示したら違いが一目でわかるね!」ということです。
(8進数という概念もありますが、16進数の方が使うことが圧倒的に多いです。) - ◆ 16進数
-
2進数の足し算は、0001 + 0001 = 0010 となり、
列(位)の合計数が2になると位が一つあがります。
16進数では名前が示す通り、同列の値が16で上の位に一つ値を増やす表記法となります。
また、10以上は表わす数字がありませんので、10 11 12 13 14 15 16 をそれぞれアルファベットで表わします。
16進数の 0 ~ 15 はそれぞれ以下の文字表記となります
0 1 2 3 4 5 6 7 8 9 A B C D E F
【例として1 byteをそれぞれの進数方式で表わすと】
これを見てわかるように、0A とか FF とか、人間の目で区別するのがかなり簡単になりましたね!2進数 10進数 16進数 00001010 10 0A 00111111 63 3F 01000000 128 80 11111111 256 FF
ようやく、0Aとか0Dとかの意味がわかってきましたね。
文字コードの形成と規格化
- ◆ ASCIIコード
-
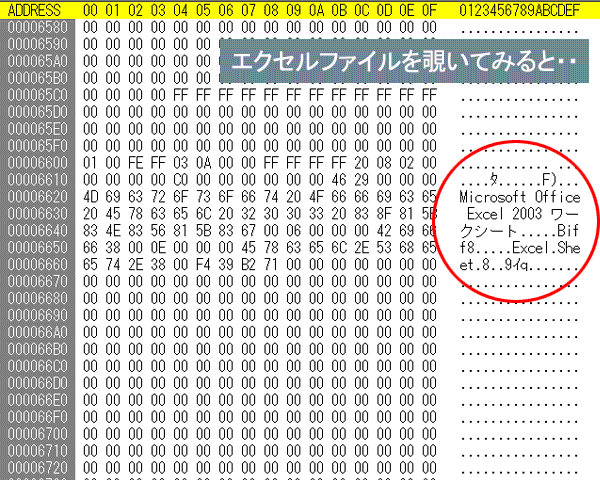 コンピューターの黎明期から 実用段階に入って来た頃、
情報を処理する際、意味ある文章・記号を記憶領域に保存するのは必然の流れでしたが、
1 byte=8 bitが定着する頃には、英数字と主要な記号は1 byteで表わせる範囲にすでに
割り当てて利用され、乱立していた各種の方式が統合されてゆきました。
コンピューターの黎明期から 実用段階に入って来た頃、
情報を処理する際、意味ある文章・記号を記憶領域に保存するのは必然の流れでしたが、
1 byte=8 bitが定着する頃には、英数字と主要な記号は1 byteで表わせる範囲にすでに
割り当てて利用され、乱立していた各種の方式が統合されてゆきました。
1 byte (8bit) では 0 と1 の並びの組み合わせは256通り可能となります。
これは2進数で0から一つづつ数えて(増やしていって)256番目が最大の数=11111111となることでもわかります。
ということは、1 byteに割り当てることが出来るキャラクタの数は256種類ということになります。
256通りの中でまず、7 bitで表わせる128種類の英数記号がASCIIコードとして 1963年にASA(アメリカ規格協会、現在のANSI) で規格として定められました。
後に、1967年に国際標準化機構(ISO)がほぼ同じ内容をISO/IEC 646 として標準化しました。
このISO646という規格には各国版があり、例えば日本版ASCIIの場合、 「バックスラッシュ」は 「\」に変わっていたりします。
プログラミングをすこしかじっておられる方ならご存知ですが、エスケープする文字の前に付ける記号が 「\」であるのは、実際バックスラッシュを指定しているわけです。
ASCIIの中をちょっと覗いてみます。
割り当てられたキャラクタを16進数で表わすと
0 → 30 1 → 31 2 → 32 ・・・ 38 → 8 39 → 9
A → 41 B → 42 J → 4A K → 4B L → 4C M → 4D N → 4E O → 4F P → 50
のようになります。
※ 1 byte=256通りの情報が表わせますが、ASCIIで制定されてない残り128通りの利用は・・?
ASCII規定以外の残り128の空き位置は拡張領域と呼ばれ、
世界各国でローカライズされ、
違った記号として利用されるようになりました。
それ以外にもISOの別の文字符号セットとして規定されてもいます。
-
さて、ASCIIとして最初に規格として定められた中には、文字、
記号以外に制御コードと呼ばれるものがありました。
その文字とは 01234567899 abc ~ xyz ABC ~ XYZ_ 記号は !"#$%&'()=-~+*>? など、 欧米で使われて来た(主にタイプライターを意識した)ものですが、制御コードとはどのようなものでしょうか?
良く知られているのが「改行コード」と、ひとくくりにして呼ばれているコードです。
-
【制御コードの例】
略語 2進数 16進数 意味 LF 0001010 0A ラインフィード、日本語では「改行」と訳しています。 本来の動作は、タイプライターの1行送りでした。 CR 0001101 0D キャリッジリターン、日本語では「復帰」と訳しています。 本来の動作はタイプライターの印字位置を先頭に戻すということでした
(紙を固定して移動する装置=キャリッジをリターンするということ)
パソコンで、Word(ワード/文章をレイアウト出来るアプリケーション)での編集作業の際、Enter
を押すと次の行の先頭にカーソルが移動しますが、この動きはLF CR
という本来タイプライターの動作を忠実に再現したもので、この時文字が入力される
代わりに、LF、CRがパソコンに記録されます。
この「改行」の制御コード群は利用されるOS(オペレーションシステム)により、
それぞれ扱いが変わってきました。
UNIX 系のOSでは、「改行」はLFの1文字のみで、
「改行・復帰」の機能を含めています。
Windows系OSでは、 CR + LF の2つのコードが並んで初めて
改行と認識します。
以前の Mac OS Ver 9までは、CRで、「改行・復帰」の機能となっています。
※ ひとくちメモ
この改行コードは結構身近な話題です。
この文章読まれている方はFTPソフト使ったことがある人がほとんどと思いますが、
UNIX系OSのウェブサーバで利用する htmlファイルは、改行コードが基本的にLFのみ
である必要があります。(UNIX系OSでは改行はLFのみなので・・)
FTPソフトに バイナリかテキストか指定する機能
があるのはこのためです。
テキストモードに設定すると、アップロード時、改行コードを
LFに変換してくれます。
さて、制御コードは他にもいくつかありますが、多くはデータ転送プロトコルのための
制御コードで、リモート端末からテキスト情報を伝える場合の便宜を図るコードなどです。
(例えば、BS/バックスペースなどで、
文字を入力・送信したけどBSを送信して直前の1文字を取り消すということ)
制御コードですが、現在は特定の通信プロトコル以外では存在感が失われつつあるようです。
マルチバイト文字
アメリカなどの英語圏では、ASCIIコードで用が足りますが、日本では
漢字をコンピュータでどのように利用するのかいろいろ考える必要が出てきました。
ASCIIの1バイト文字に対して、日本、中国などが使っている漢字の
種類は16万文字にも及ぶらしく、当然1バイトでは表せません。
そこで、2バイト以上の組み合わせで文字を符号化することになったわけですが、この文字(文字種)の
ことをマルチバイト文字と呼ぶようになりました。
以前(30年位前かな?)、EUC-JP、シフトJISなどが主流の時は
2バイト文字と呼んでいた時期もありましたが現在は死語になりました。
マルチバイト文字と呼ばれるようになったのは、ここ10~20年位のことでは
ないかと思います。
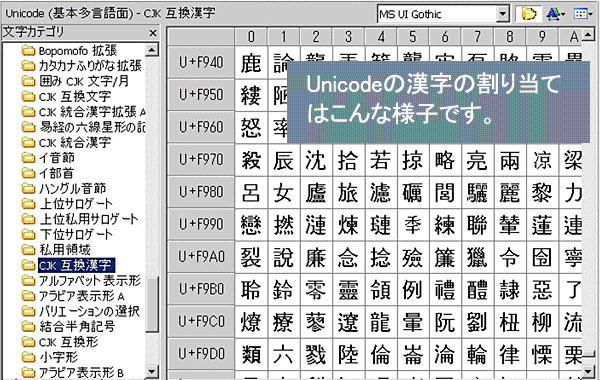
コンピューター・通信機器の進化の途上において「日本語(文字)を効率的に利用、
処理するかはどうしたらいいか?」 IT黎明期の日本では大きな課題でした。
手始めに、カタカナを使えるようにしようということで、ASCII
コードの中で制御文字以外にカタカナを割り振り、エスケープシーケンスにより切り替えて
利用するという方法が考案されました。
※ エスケープシーケンスとは
制御文字(キャラクタ)ESC/1bとそれにつづく1バイト文字を出力(入力)することで、
それ以降のキャラクタの文字(符号化)セットの意味を変更出来るように考えられた機構、機能。
例えば、 ESC ( B のコードの並びがあった時は、以降から1byte
の意味が変わりますという合図となる。
このカタカナの符号化は、1969年JIS C 6220(俗称 ANKコード)として
制定されました。その後1987年に カテゴリなどの変更によりJIS X 0201と変更されました。
そういった流れの中、新聞の編集システムやコンピューター・通信機器など扱う会社において、
日本語をどのように符号化するかを独自に模索していたのでした。
漢字の符号化という面で進んでいたのが新聞業界に関連したシステムです。
例えば、1959年に共同通信社と加盟社が策定した統一文字コード
CO-59(六社協定新聞社用文字コード=2,304字を6単位2列で符号化したもの)
を使用して、記事本文を配信・受信・組版するシステムが始まりました。
1977年にはCO-77としてバージョンアップしましたが、これは後に
日本のJIS規格の礎となった規格です。
他方、写研(印刷物の写植文字・フォント、写植機、組版装置など製造・制作する会社)
は、独自に13bitで文字を符号化する新たなコード体系を作りそれをSKコード
(SK72/78)と名付け、電子組版システムに採用しています。
詳細は分かりませんが2万字にも及ぶようです。
公的な規格としては、1978年にやっとのことでJIS C 6226
(いわゆるJIS漢字コード 後にJIS X 0208
と変更される)が制定されました。
これも、それまでの民間の規格したものをベースにやっとのことで誕生したものでした。
紆余曲折の日本語コード
- ◆ JISコード(通称)の普及
-
最初に日本で漢字を符号化したものであるので、もちろんすべてのベースとなってはいるものの、
7bitコード体系のASCIIで規定されている場所ににカタカナを割り当てたり、
文字判定はエスケープシーケンス処理が必要であることなど
複雑な部分が多く今から思えばスマートなものではなかったようです。
ですが、メールなどのプロトコル(SMTP)は当初7bitキャラクタでの 処理が前提であったため、メールなどのエンコード文字セットの指定は、JIS (ISO-2022-JP)を指定することが必然でありました。
今はメール送信の文字コードに、UTF-8も利用可能になっています。 (SMTPの拡張は、RFC6530、RFC6531、RFC6532、RFC6533、でいろいろ策定がすすみほぼ決まりのようです )
現在、存在意義としてメールでの利用があったのですが、メールでもUTF-8が標準に向かっている今、 いよいよ影が薄くなって来たコードと言えましょう。 - ◆ シフトJIS
-
1980年代はパソコンが16ビットCPUを採用したしたこともあり、日本語表示可能な
ハードウェアを備えたパソコンが次々と発売されました。
すでに、JIS C 6220(後にJIS X 0201)、JIS C 6226 (後にJIS X 0208)が制定されてはいましたが、日本のPC黎明期の先人たちは その2つの文字の規格をどうにか融合できないかと考えました。
さらには、処理を複雑にしているエスケープシーケンスを使わず利用出来るように することも想定していました。
1982年に漢字の符号位置を移動(シフト)してなんとかエスケープシーケンスなしで、 漢字を表わせるShift_JIS(シフトジス)が誕生しました。
Shift_JIS(シフトジス)の誕生は、アスキー、マイクロソフト、 三菱電機などが関わりました。
きっかけは、三菱電機のMULTI-16開発時に、Basicインタープリタには すっきりした日本語の文字コードを搭載できないかということだったらしいです。
当時シアトルマイクロソフトUSでBASICインタプリターの実装を行うエンジニア だった山下良蔵さんの回顧記録に記述されています。
記録はこちら、 山下良蔵さんのシフトJIS コードについての記述
これによると、ベースは山下良蔵が作成し、以降まわりからの助言なども得て、作り上げられて いったのが良くわかります。
この時以降、日本のパソコンはシフトJISがスタンダードになります。
現在(2016年9月)、ウェブでの利用においては、UTF-8が標準となっていますが、エクセル、テキスト など、Windows搭載パソコンではまだまだ現役のようです。 - ◆ EUC-JP
-
別の動きとして、インターネットではネイティブOSとも言えるUNIX系OSの関係者の手で、
システムで利用する日本語文字コードの制定が進められました。
これは、EUCコード体系(Extended UNIX Codeの略)としてまとめられ、 特に日本語コードは、EUC-JPとされました。 ベースはJIS X 0208で、 それにASCIIコードを加えたものでした。
近年まで、UNIX系OSでは日本語処理系のスタンダードな文字コードでしたが、 現在は後述するUnicode(UTF-8)に取って代わられています。
- ◆ Unicode(ユニコード)
-
シフトJIS にしろ、EUC-JP にしろ、
PCのアプリで日本語を表示は出来ますが、日本語以外のマルチバイト文字は同時に
同じ画面で表示出来ません。
例えば、すこし前まで日本語と中国語は同じブラウザの同じページで見れませんでした。
そのような不便を解消すべく、Unicode(ユニコード)が制定され、 近年急速に普及して来ました。
Unicodeは、「世界で使われる全ての文字を一つの文字集合で利用出来る ようにしよう」という主旨で生まれました。
その起源は意外と早く、すでに1980年代にゼロックス社が提唱し、マイクロソフト、 アップル、IBM、 サン・マイクロシステムズ、ヒューレット・パッカード、 ジャストシステムなどが参加するユニコードコンソーシアム により作られました。
1993年に、国際標準との一致が図られ、当初案から大幅に変更されて、 ISO/IEC 10646が制定されました。
Unicodeは、1980年代当時、16ビット固定長(65,536通りの文字をマッピング出来る)で表わす 予定でしたが、コード化を進める過程で各国からの追加要求が頻出し、とてもこの範囲 に収まらなくなり、必然として16ビットから広げることになりました。
ただ、それまで16ビットの文字コード処理を前提にすでに成熟期にあるOSや、高級言語の仕様を 変更することはかなり面倒なことになるとして、それらを変更せずに割り振る方法が考えられました。
それが、サロゲートペアと命名された仕様で、16ビットの領域1024文字分を 2区画決め、それぞれの区画から1個ずつ番地を割り振れば、1024 × 1024 = 1,048,576文字分 表わすことが出来るというものです。
このような間接的に文字コードを表すようになったことから、文字を特定する計算式の方法が いくつか生まれることになりました。 いくつかある計算の方法を「文字符号化方式」といいます。
良く使われるものに、UTF-7 UTF-8 UTF-16 UTF-32 などがあります。
Web関連では圧倒的にUTF-8 が採用されています。
これは、8bitベースの処理が可能で複雑な計算処理なども無いため、 使い勝手が良かったためと思われます。
どちらにせよ、今後はこのUnicode(ユニコード)がスタンダードになる と思われますので私たちウェブに従事するものにとっては、やり易くなったと感じています。
ちなみに、Windowsの「メモ帳」でファイルを保存する時、文字コードを選択できますが、 それぞれの選択したコードの意味は、
ANSI → シフトJIS (日本の工業規格と同等であるが一部MS独自の違う部分がある)
Unicode → ユニコード( UTF-16のエンコード)
Unicode big endian → ユニコード (UTF-16のエンコードでバイト並びが逆になるもの)
UTF-8 → ユニコード(UTF-8のエンコード)
ということです。
※ ANSIとしているのは・・
実際は、シフトJISであるのに「ANSI」としているのは、
7bit部分がASCII
(ANSIが制定した)と完全に互換性あるので、そのことを指してのことと、
特にWindowsではデフォルト文字コードがシフトJISということで、「ANSI」という
表記にしていると思われます。
※ メモ帳でHTMLを作成するのは注意が必要
メモ帳でも HTMLファイルの編集が出来ますが、保存する文字コードがUnicodeの場合、
BOMと呼ばれる特殊な情報がファイル先頭に付加されますので注意して下さい。
BOMは、Unicodeで記述されているか? また、big endian
かそうでないかを判定するための記号のようなものですが、HTMLファイルには不要で、
付加されていた場合レイアウト崩れなど起こす場合がありますので注意して下さい。
BOMの実体はというと、ファイルの最初に、FF FE(UTF-16 リトルエンディアン)、
FE FF(UTF-16 ビッグエンディアン)、EF BB BF(UTF-8) というバイト列が追加されることです。
HTMLは出来れば、専用のテキストエディタでおこないましょう。
今後、符号化方式の変更などあるかもしれませんが、基本このコードが終着点と思います。
後述
テキストについての説明はいかがだったでしょう?
説明が分かりにくい部分もあったかと思いますが、文章があまりに長くなっても読む気が無くなると思いまして、
できるだけ短文で簡潔にしたつもりです。
テキストファイルの理解はすなわち、ウェブの理解にもなります。 すこしでもお役にたてれば幸いです。

